AI literacy for project practitioners: the skill matrix I’m using to prepare

I’ve been spending a good chunk of my free time catching up on AI.
Not because I want to become an AI engineer. I’m doing it because I’m curious and because I can see professional challenges coming where this knowledge will matter. I want to understand how AI works and what it changes in projects and delivery strategy.
Today, I use ChatGPT and Gemini almost daily. They help me research, write and think. But until recently, I used them the same way I use most software: I learned the buttons, not the foundations. That worked fine for a while. But after years in delivery, one question kept coming up:
Is a project where AI is part of the product the same as a project delivering a traditional, non-AI product?
My first instinct was: “I’ll learn it when the project comes along.”
But I wasn’t so sure that wouldn’t be too late. AI was uncharted theory for me. I knew I didn’t know enough and I also knew there was a lot to know. And even before I could put it into clean words, I had a strong hypothesis: once AI is part of the product, delivery changes. Not just technically, but in requirements, testing, governance, rollout and support.
So this post is my starting point.
- Not a technical deep dive
- Not war stories from delivered AI projects
- A pre-flight checklist for project practitioners who want to be equipped before the fun starts
I split this into two posts. This first one explains the approach and the skill matrix. The second post will share the curated resources I used.
My starting point and constraints
I’ve been delivering projects and products on the business side for more than 15 years. I have a background in business informatics, but I’m not a deeply technical person. I’m strongest when I can understand technology conceptually, connect dots and translate it into delivery decisions.
I’m a frequent user of ChatGPT and Gemini, but I never really sat down to understand the basics properly. I also had a rough glimpse of more advanced concepts like agents, orchestration and LLMOps, which made it obvious this is not “just another software feature”.
One more important point: I have not delivered an AI-powered project in practice yet. Consider this a pre-delivery map, not a post-project report. Think of it as preparation so you don’t have to learn the fundamentals while the project is already on fire.
This post is for you if you are a project manager, product manager, business analyst or in a similar role delivering products or projects without heavy AI involvement so far. It’s also for you if you lead a delivery team that is about to use AI as part of the product rather than just as an internal productivity tool.
Defining the target: what does “AI literacy for delivery” mean?
After my first round of research, I noticed two problems immediately:
- If I “just start reading”, I’ll get lost fast.
- Even if I keep reading, I won’t know when I’ve learned enough.
So I reframed the goal. My main question became:
How does AI in the product change the delivery framework, and how do I stay able to make good decisions?
That touches everything: requirements, testing, deployment, project approach, risk management, compliance, even pricing and value cases. Without a minimum level of literacy, it’s easy to either overtrust the system (“it’s smart, it’ll work”) or overcontrol it with classic mechanisms that simply don’t fit probabilistic behaviour.
That’s when I decided to define a target skill set first.
The AI skill matrix for project practitioners
I created a skill matrix as a thinking tool. Not as a certification model. Not as a claim that this is “the one true curriculum”. For me, it was a clear target to work against.
I also see it as an intermediate state. Once you have the basics, new questions appear naturally, for example:
- Delivery method: How do sprint reviews and “definition of done” change when output quality is statistical, not deterministic?
- Quality assurance: What does “testing” mean when your system can produce multiple valid answers and also occasionally invents things?
- Release and support: What does incident management look like when failures show up as degraded behaviour, drift, rising cost or latency spikes rather than a clear bug?
- Operating model: Which roles become critical (evaluation, prompt ops, data stewardship, compliance) and which assumptions break?
The three pillars
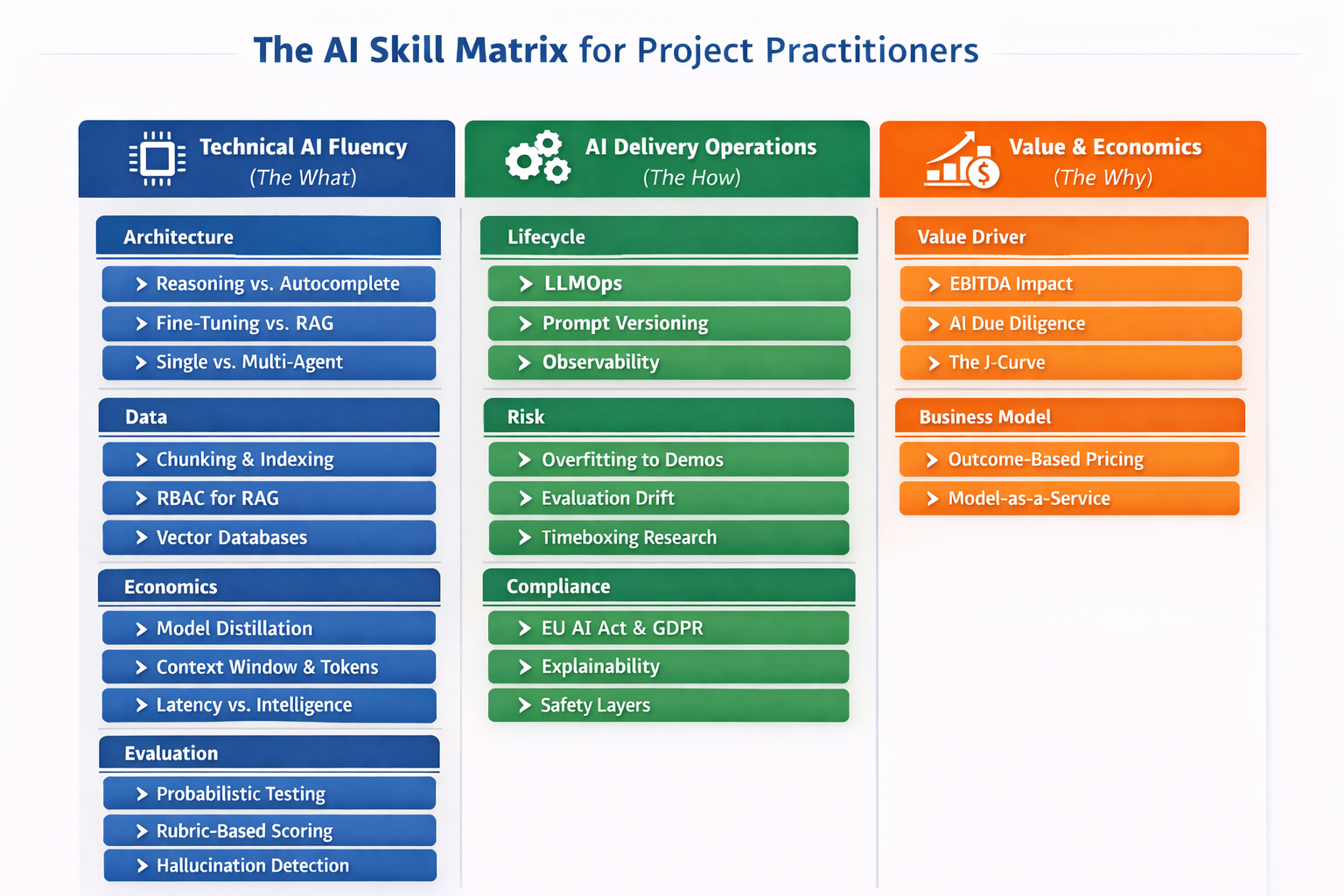
The matrix has three pillars:
- Pillar 1: Technical AI fluency (the “what”)
You don’t need to implement models, but you need to understand how they behave so you can set expectations and spot risks. - Pillar 2: AI delivery operations (the “how”)
How you version, test, monitor and run AI capabilities in production. This is where “demo vs reality” often collapses. - Pillar 3: Value and economics (the “why”)
How AI changes value creation, business cases and pricing models. This is where many projects win or fail before the first line of code.
Here is the detailed matrix as I’m using it right now:
Pillar 1: Technical AI fluency (the “what”)
Architecture
- Reasoning vs. Autocomplete: Grasp the probabilistic nature of "Next-Token Prediction" to distinguish between genuine logical reasoning and simple statistical mimicry.
- Fine-tuning vs. RAG: Master the strategic decision tree: when to inject knowledge via retrieval (RAG) vs. when to alter model behavior via training (Fine-tuning).
- Single vs. Multi-Agent: Understand orchestration patterns where "Manager" agents delegate tasks to "Worker" agents to solve complex, multi-step problems.
Data
- Chunking & Indexing: Learn how raw text is split, embedded and indexed to ensure the AI retrieves the exact right paragraph for a query.
- RBAC for RAG: Understand "Role-Based Access Control" patterns within the retrieval layer so the AI respects user permissions (e.g., hiding payroll data from interns).
- Vector Databases: Understand the role of semantic search engines (Pinecone, Weaviate) as the long-term memory that powers enterprise AI.
Economics
- Model Distillation: Learn the cost-optimization strategy of using a large "Teacher" model (GPT-4) to train a small, cheap "Student" model for specific tasks.
- Context Window & Tokens: Master economics of input/output tokens to manage costs and understand the "memory limit" of a conversation.
- Latency vs. Intelligence: Evaluate the trade-off between "Time-to-First-Token" (speed) and reasoning depth to select the right model for the use case.
Evaluation
- Probabilistic Testing: Understand why traditional "Pass/Fail" unit tests break in AI and how to design tests for non-deterministic outputs.
- Rubric-based Scoring: Learn to define qualitative criteria (Politeness, Factualness) and use "LLM-as-a-Judge" to grade responses automatically at scale.
- Hallucination Detection: Understand common metrics (Faithfulness, Relevance) to flag when an agent invents facts or ignores the provided context.
Pillar 2: AI delivery operations (the “how”)
Lifecycle
- LLMOps: Define the infrastructure pipeline required to version, test and deploy prompts and agents reliably, moving beyond "running on a laptop."
- Prompt Versioning: Treat prompts as software assets (using Git/Registry) to track changes, roll back bad updates and maintain stability.
- Observability: Master the use of tracing tools (LangSmith, Arize) to visualize the step-by-step execution path of an agent when it fails.
Risk
- Overfitting to Demos: Identify "Demoware", systems that work perfectly on 5 curated examples but fail on real-world edge cases and messy data.
- Evaluation Drift: Manage the operational risk where a model update (e.g., from OpenAI) suddenly breaks your legacy prompts and workflows.
- Timeboxing Research: Enforce strict delivery timelines to prevent engineers from falling into the "endless tinkering" trap of optimizing prompts forever.
Compliance
- EU AI Act & GDPR: Navigate the regulatory landscape, specifically "High Risk" vs "Limited Risk" categorization and the "Right to be Forgotten" in vector stores.
- Explainability: Ensure systems can provide an audit trail or citation for every answer to satisfy enterprise compliance teams.
- Safety Layers: Know common guardrail layers (content filtering, PII masking) to prevent jailbreaking, toxicity or data leakage in outputs.
Pillar 3: Value and economics (the “why”)
Value Driver
- EBITDA Impact: Translate technical AI capabilities into specific financial metrics: FTE reduction, revenue acceleration or margin expansion.
- AI Due Diligence: Develop a framework to assess a project’s "AI readiness" (data quality, tech debt, talent).
- The J-Curve: Articulate the productivity J-curve: managing the initial dip in efficiency during adoption before the gain.
Business Model
- Outcome-based Pricing: Shift pricing strategy from "time & materials" or "per seat" to "per successful outcome" to capture the value of automation.
- Model-as-a-Service: Package ongoing monitoring, tuning and model updates as a recurring revenue stream rather than one-off project fees.
For a while, I wasn’t sure this matrix approach was right because it doesn’t start with the classic “How LLMs work…” storyline.
But once I started searching for learning materials, it clicked. A target-state approach helped me avoid random browsing. It also made it easier to find sources that matched what I actually need for delivery. And the interesting thing is: you still end up touching the fundamentals early, just in a more purposeful order.
If you want to create your own learning path, you can use this matrix as a map.
How I used AI to build the learning path
To build the matrix, I leaned heavily on ChatGPT and Gemini. It worked well, but I needed both to get to a result I liked.
My personal impression:
- Gemini (3) was better at finding and suggesting sources.
- ChatGPT (GPT 5.2) was better at shaping the overall framework and turning a messy set of ideas into something structured.
I probably could have landed somewhere similar with only one of them, but using both felt like getting two different personalities in the room. Gemini, especially the latest version I used, can be a bit too motivated when asked for “a simple structure”. It often adds extra layers and ideas I didn’t ask for. I tried to rein it in with prompts, but with limited success.
Once the matrix existed, I was tempted to let the models generate summaries for every topic. After trying this for a few areas, I defaulted back to human-written articles. Deep research features are impressive, but for foundational learning, carefully curated writing by humans felt more enjoyable and more appropriate.
Where the models shined for me was as a companion while reading: explaining abbreviations, clarifying a concept, giving an example or challenging my understanding. In that mode, both tools did the job well.
What comes next
This post was about the “why” and the “what”: why AI changes delivery and the skill matrix I’m using to get ready.
In the next post, I’ll share the curated set of resources I’m working through, structured along this matrix. Not exhaustive. Just enough to reach delivery-level AI literacy without drowning in content.
If you’re on a similar path, feel free to take the matrix, adapt it and challenge it. I expect mine will evolve the moment theory meets practice.



